
👋🏻Hi, I’m Ge Yuan. I’m a second year Ph.D student from the Department of Computer Science and Technology at Northeastern University, China. I work at Natural Language Processing Lab under the supervision of Prof. Tong Xiao and Prof. Jingbo Zhu.
My research interest includes speech language process, voice-centric interaction, and language modeling. I have published more than 10 papers at the top international AI conferences (ACL, EMNLP, AAAI, etc.) with total google scholar 

🥳 News
- 2026.07: 🏆 “On the Emotion Understanding of Synthesized Speech” was honored with SAC Highlight Award @ ACL 2026.
- 2026.06: Started my internship at Qwen-omni multilingual Group.
- 2026.04: 🎉 Two papers (1 Top 5% of accepted papers by Main Conference and 1 Fingdings) accepted by ACL 2026.
- 2026.02: 🎉 Four papers accepted by ICASSP 2026.
- 2025.11: 🎉 Two papers accepted by AAAI 2026.
- 2025.08: 🎉 One paper (Main Conference) accepted by EMNLP 2025.
- 2025.06: 🎉 One paper (Oral) accepted by NLPCC 2025.
- 2026.02: 🎉 One paper accepted by ICASSP 2025.
- 2024.08: 🎉 One paper (Main Conference) accepted by EMNLP 2024.
- 2024.06: Finished my internship at Huawei.
- 2024.02: 🎉 One paper accepted by LREC-COLING 2024.
- 2023.06: Started my internship at Huawei.
📝 Publications
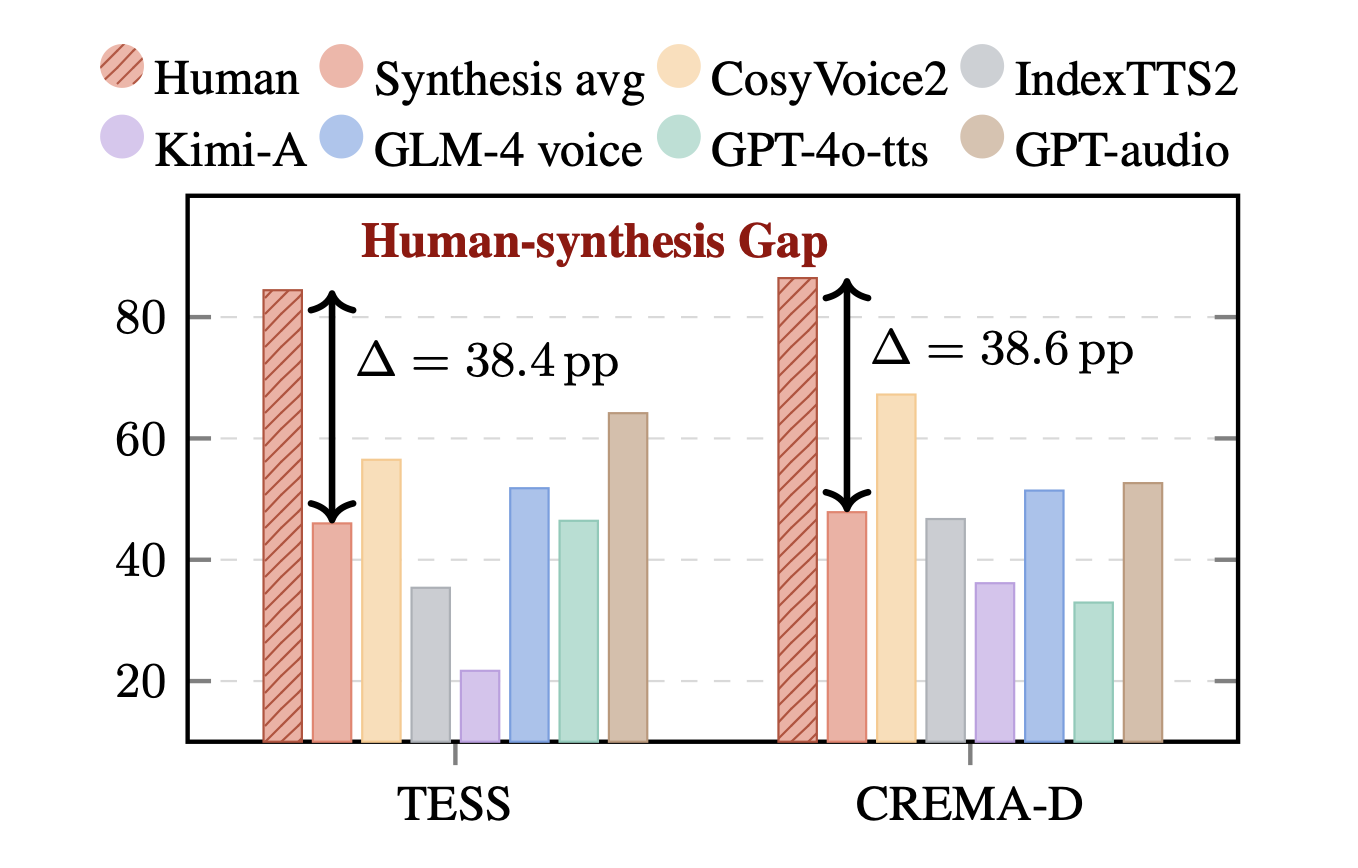
On the Emotion Understanding of Synthesized Speech
Yuan Ge, Haishu Zhao, Aokai Hao, Junxiang Zhang, Bei Li, Xiaoqian Liu, Chenglong Wang, Jianjin Wang, Bingsen Zhou, Bingyu Liu, Jingbo Zhu, Zhengtao Yu, Tong Xiao
🏆 SAC Highlight Award
SAC rating: 10: Top 5% of accepted papers, seminal paper.
Average Overall Assessment: 4.00 (Min: 3.5, Max: 4.5); Meta: 3.5
- Synthetic audio is becoming increasingly common, yet audio understanding tasks have largely overlooked it. It is widely believed that emotion understanding models learn fundamental representations that transfer to synthesized speech, making emotion understanding results a plausible reward or evaluation metric for assessing emotional expressiveness in speech synthesis. In this work, we find that current SER models can not generalize to synthesized speech, largely because speech token prediction during synthesis induces a representation mismatch between synthesized and human speech. Moreover, generative Speech Language Models (SLMs) tend to infer emotion from textual semantics while ignoring paralinguistic cues. Overall, our findings suggest that existing SER models often exploit non-robust shortcuts rather than capturing fundamental features, and paralinguistic understanding in SLMs remains challenging.
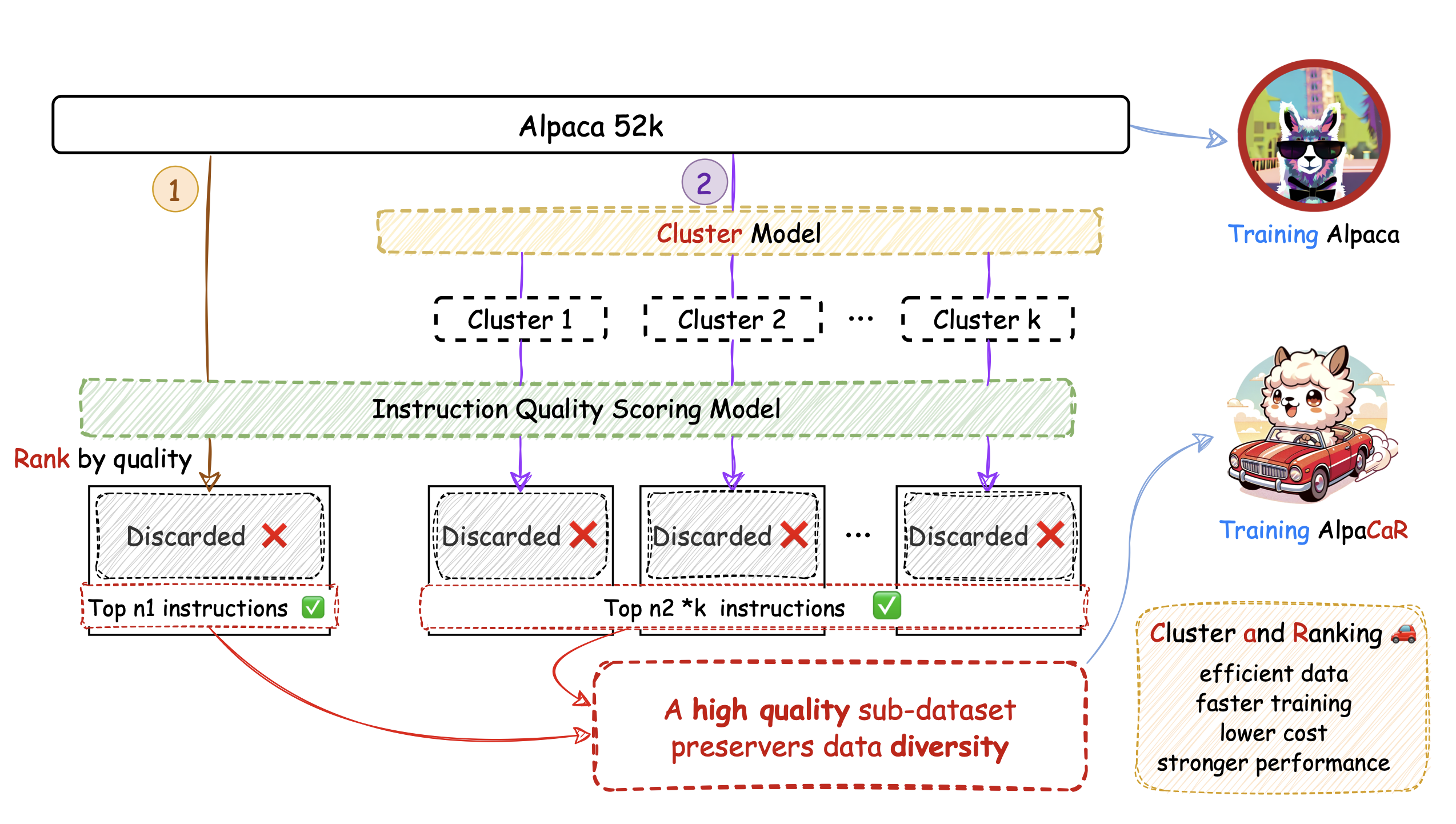
Yuan Ge, Yilun Liu, Chi Hu, Weibin Meng, Shimin Tao, Xiaofeng Zhao, Hongxia Ma, Li Zhang, Boxing Chen, Hao Yang, Bei Li, Tong Xiao, Jingbo Zhu
Cited by Google DeepMind, Meta GenAI, Baichuan Technical Report, CMU, and other organizations;
Email Invitation for Internships at Tongyi Lab;
Introduced in Liu Cong’s NLP WeChat Official Account(刘聪NLP);
Introduced in the YSSNLP 2024 Tutorial;
- We discuss the importance of data quality and data governance, and design a data filtering method that takes both data quality and diversity into account. Our method achieves open-ended dialogue performance that is 32.1% better than the baseline using the full dataset on the Alpaca dataset, while utilizing only 1.96% of the data. More importantly, we demonstrate that the benefits of data governance during the SFT stage remains significant even as the number of parameters of the pre-trained model increases (7B–30B) and the model’s pre-training capabilities improve (Llama 1–Llama 3). As of 2023, there is still no consensus on the impact of data quality on advanced LLMs.
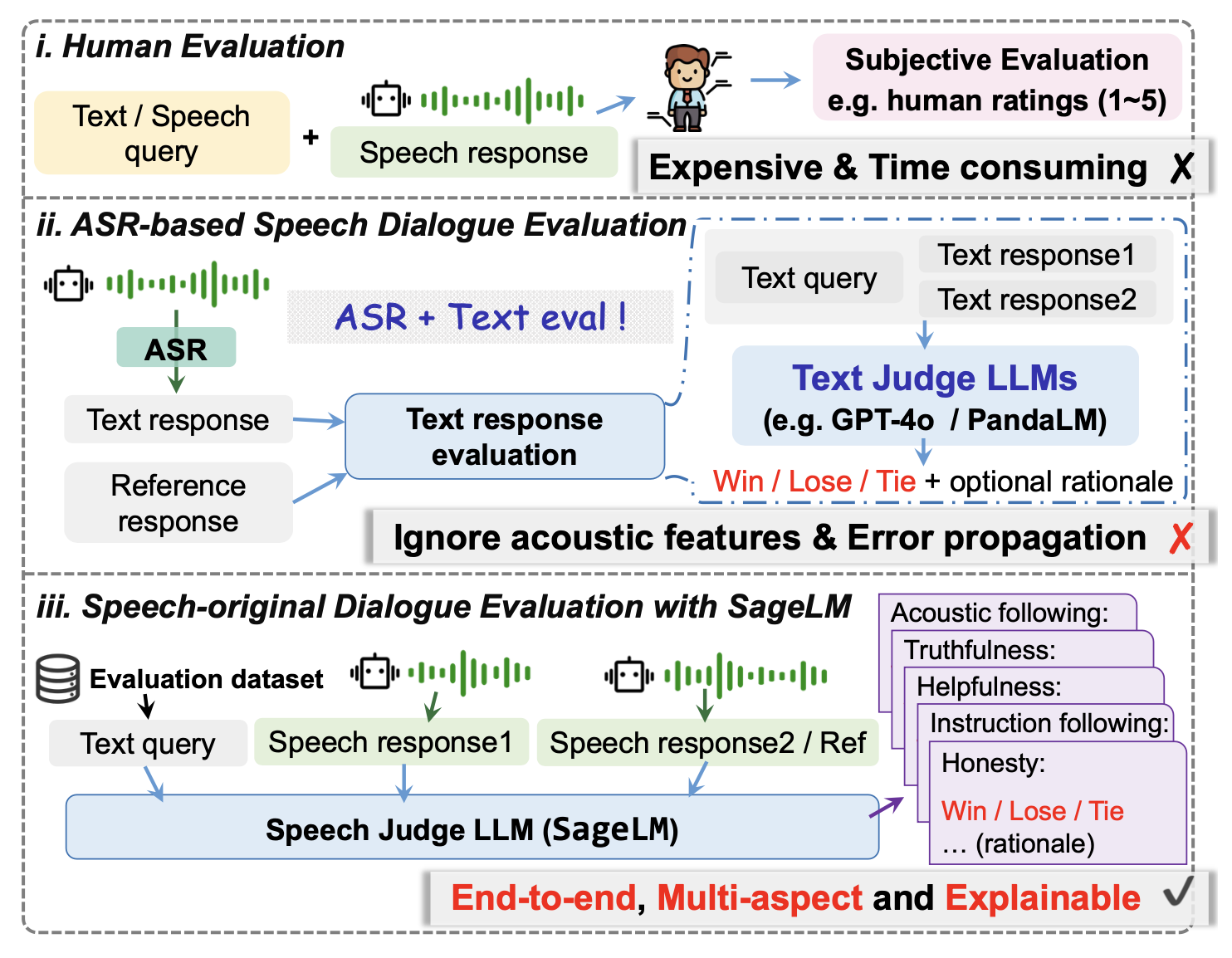
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Yuan Ge, Junxiang Zhang, Xiaoqian Liu, Bei Li, Xiangnan Ma, Chenglong Wang, Kaiyang Ye, Yangfan Du, Linfeng Zhang, Yuxin Huang, Tong Xiao, Zhengtao Yu, JingBo Zhu
- Current evaluations of Speech-to-Speech (S2S) models rely on human evaluation or “ASR + text evaluation.” This approach 1. suffers from cascading errors; 2. ignores the paralinguistic information inherent in spoken dialogue. Therefore, we constructed a dataset and trained a multidimensional, end-to-end, interpretable speech evaluation model. We found that using results plus explanations for SFT within the LLM-as-a-judge paradigm yields better performance than GRPO. Furthermore, we comprehensively tested SageLM’s evaluation capabilities and preliminarily validated its performance as a reward model.
- ICASSP 2026, MTP-S2UT: Enhancing Speech-to-Speech Translation Quality with Multi-token Prediction \ Jianjin Wang, Runsong Zhao, Xiaoqian Liu, Yuan Ge, Ziqiang Xu, Tong Xiao, Shengxiang Gao, Zhengtao Yu, Jingbo Zhu
- ICASSP 2026, StyleBench: Evaluating Speech Language Models on Conversational Speaking Style Control \ Haishu Zhao, Aokai Hao, Yuan Ge, Zhenqiang Hong, Tong Xiao, Jingbo Zhu
- ICASSP 2026, Attention2Probability: Attention-Driven Terminology Probability Estimation for Robust Speech-to-Text System \ Yanfan Du, Jun Zhang, Bin Wang, Jin Qiu, Lu Huang, Yuan Ge, Xiaoqian Liu, Tong Xiao, Jingbo Zhu
- ICASSP 2026, SUBQRAG: Sub-Question Driven Dynamic Graph RAG \ Jiaoyang Li, Junhao Ruan, Shengwei Tang, Saihan Chen, Kaiyan Chang, Yuan Ge, Tong Xiao, Jingbo Zhu
- AAAI 2026, WaveEx: Accelerating Flow Matching-based Speech Generation via Wavelet-guided Extrapolation \ Xiaoqian Liu, Xiyan Gui, Zhengkun Ge, Yuan Ge, Chang Zou, Jiacheng Liu, Zhikang Niu, Qixi Zheng, Chen Xu, Xie Chen, Tong Xiao, Jingbo Zhu, Linfeng Zhang
- EMNLP 2025, Step-level Verifier-guided Hybrid Test-Time Scaling for Large Language Models \ Kaiyan Chang, Yonghao Shi, Chenglong Wang, Hang Zhou, Chi Hu, Xiaoqian Liu, Yingfeng Luo, Yuan Ge, Tong Xiao, Jingbo Zhu
- NLPCC 2025, StoryBench: A Dataset for Diverse, Explainable, Multi-hop Narrative Text-to-Image Generation \ Yuan Ge, Kaiyang Ye, Saihan Chen, Aokai Hao, Xiangnan Ma, Kaiyan Chang, Tong Xiao, Jingbo Zhu
- ICASSP 2025, A Modular-based Strategy for Mitigating Gradient Conflicts in Simultaneous Speech Translation \ Xiaoqian Liu, Yangfan Du, Jianjin Wang, Yuan Ge, Chen Xu, Tong Xiao, Guocheng Chen, Jingbo Zhu
- LREC-COLING 2024, RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners \ Chi Hu, Yuan Ge, Xiangnan Ma, Hang Cao, Qiang Li, Yonghua Yang, Tong Xiao, Jingbo Zhu
🎖 Honors and Awards
- 2026.07 🏆 “On the Emotion Understanding of Synthesized Speech” was honored with SAC Highlight Award @ ACL 2026.
- 2024.10 Huawei Smart Base Scholarship(华为智能基座奖学金).
- 2022.06 Selected for the “Northeastern University–Huawei Digital and Networking Elite Class”(东北大学—华为数通菁英班) at the School of Future Technologies(未来技术学院).
📖 Educations
- 2024.09 until now, Ph.D, Northeastern University, under the supervision of Prof. Tong Xiao and Prof. Jingbo Zhu.
- 2022.09 - 2024.06, Master, Northeastern University, under the supervision of Prof. Tong Xiao and Prof. Jingbo Zhu.
- 2018.09 - 2022.06, Undergraduate, Northeastern University.
💻 Internships
- 2026.06 until now, Research Intern, Alibaba Qwen Group(Hangzhou, China).
- 2023.08 - 2024.08, Research Intern & LLM Application Engineer, Huawei(Beijing, China).